Create Stunning Product Videos with AI
Meet Trainn: An AI-powered video creation tool to create videos of your digital product in 5 minutes and at scale.
Free for 14-days. No credit card required.
Related terms
Text-to-Speech Converter
What is a Text-to-Speech Converter?
A Text-to-Speech converter (TTS) refers to an AI-based technology that automatically converts input text into human-like speech. TTS synthesizes natural vocal audio matching diverse needs from languages, accents, tones, and speeds using advanced deep learning algorithms instead of recording studios and human voice artists.
From generating narrations for videos to building conversational assistants, text-to-speech technology enables scalable vocalization across any use case through a user-friendly editor interface.
Benefits of using a Text-to-Speech Converter
Key advantages of text-to-speech converters include:
- Rapid narration output automated-Make voiceovers fast and easy.
- Scales to unlimited vocal content needs-Create as many voiceovers as you want.
- Supports content localization for global learners-Choose from different languages and accents to connect with learners across the globe. Read why content localization is the secret element that will elevate your performance.
- Handles complex name or word pronunciation-Pronounce any name or word correctly.
- Facilitates personalization through voice building-Customise your voice to your liking.
- Significantly lower costs than studios and artists-Save money on voiceover production.
- Quick iteration supporting agile content strategies-Update and improve your voiceovers quickly.
- Text-to-speech solutions enhance productivity and optimize budgets through versatile vocalization capabilities.
How do Text to Speech Videos Work?
Powerful deep neural networks convert Text-to-Speech using human speech data to train predictive models. The AI algorithmically analyses textual input to determine optimal pacing, emotion, and inflections for the narration. High-fidelity vocal audio is then generated matching the specifications using sophisticated speech synthesis techniques for seamless listening experiences.
What are the challenges of creating a Text-to-Speech Converter?
However, developing accurate and robust text-to-speech technology poses complex challenges including:
- Achieving sufficient emotional expressiveness
- Enabling support for niche lexical terms
- Reducing synthesized speech artifacts fully
- Retaining accuracy across long input paragraphs
- Preventing infusion of harmful biases into output
- Maintaining rigorous data privacy safeguards
How to select the right Text-to-Speech Converter?
When evaluating text-to-speech solutions, consider aspects like:
- Custom voice-building options - This means the ability to create your voice or modify an existing one to suit your preferences and goals. For example, you may want to change the pitch, speed, tone, or accent of the voice.
- Supported language breadth - This means the number and variety of languages that the text-to-speech converter can handle. For example, you may want to convert text in different languages or dialects or use multilingual voices.
- Speech accuracy ratings - This means the quality and reliability of the speech output that the text-to-speech converter can produce. For example, you may want to avoid errors, glitches, or unnatural sounds in the speech.
- Available voice personas - This means the selection and diversity of the voices that the text-to-speech converter can offer. For example, you may want to choose from different genders, ages, styles, or emotions for the voice.
- Tool accessibility and interface - This means the ease and convenience of using the text-to-speech converter. For example, you may want to access the tool online or offline, on different devices or platforms, or with different features or functions.
- Data security and compliance - This means the protection and privacy of the data that you use or generate with the text-to-speech converter. For example, you may want to ensure that your data is encrypted, stored, or deleted securely, or that it complies with the relevant laws or regulations.
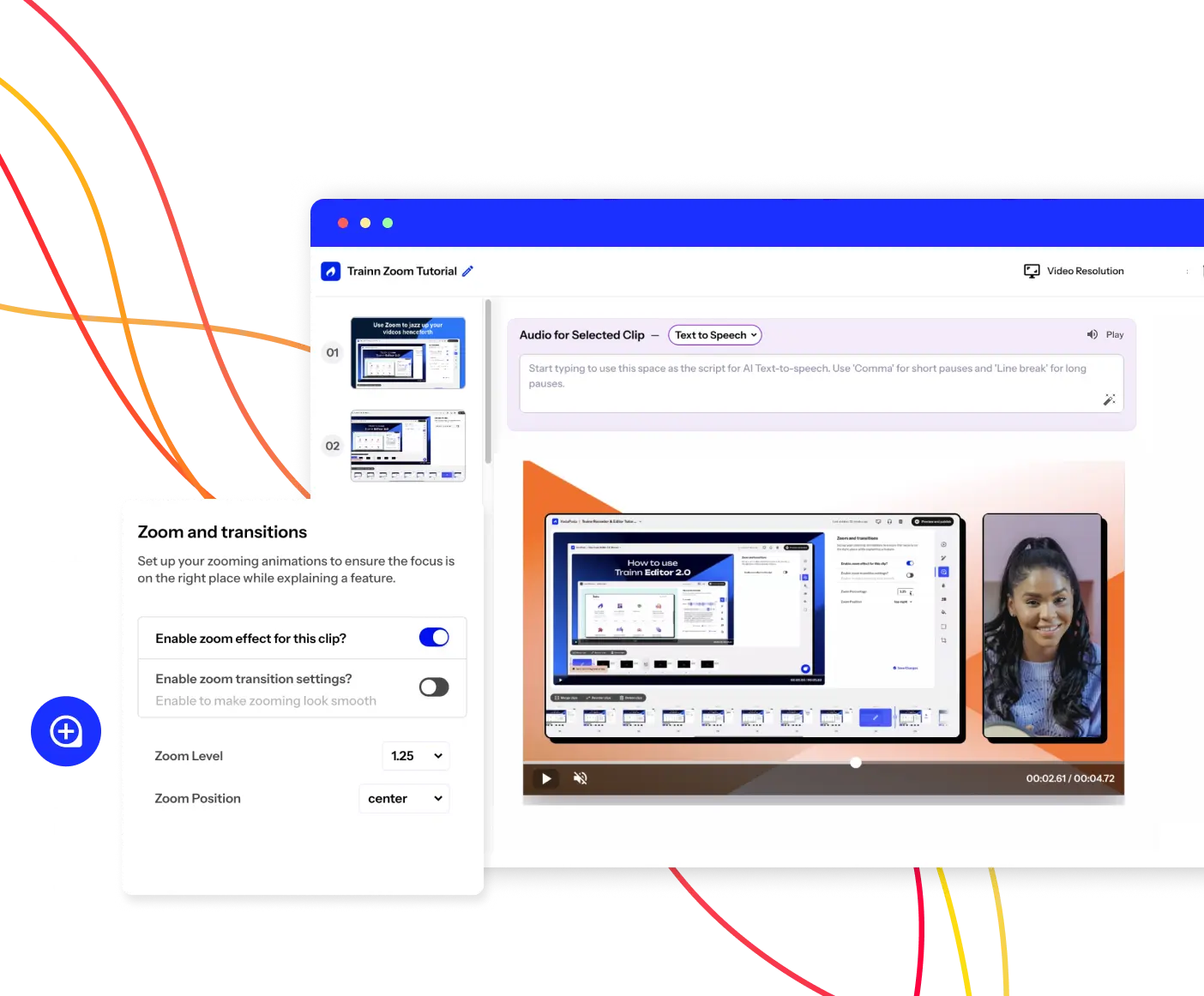
When using AI-powered video creation software like Trainn, you can leverage the built-in Text-to-speech converter that automatically turns your script into human-like voiceovers in over 20 languages.
FAQs
How is text-to-speech technology regulated?
Providers follow extensive internal governance around ethics to prevent potential misuse alongside external industry regulations.
What future innovation is expected in text-to-speech?
R&D continues to focus on even more human-like speech backed by multimodal inputs beyond just text for context.
Is text-to-speech only for English?
No, text-to-speech supports multiple languages, enhancing global accessibility. Video creation tools with built-in text-to-speech converters like Trainn offer support for over 20+ languages including Hindi, Spanish, American English, and more.
Explore More



Create Engaging Videos Faster With Our AI-powered Video Creation Tool
Without design or video skills.
Create your first video now